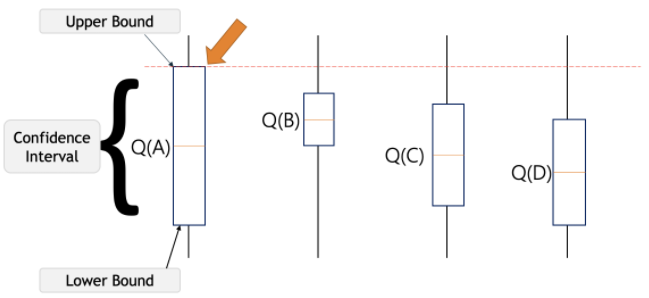
Exploration in Reinforcement Learning
강화학습에서는 Exploration(탐험)이 굉장히 중요하다. Action value estimation에는 불확실성이 항상 존재하기 때문에 Exploration을 통해서 궁극적 학습 목표를 달성하고자 한다.
ε-greedy method가 Exploration과 Exploitation을 강제적으로 ε의 확률로 balancing하는 것이다. ε-greedy method에서의 Exploration은 선택 가능한 Action 중에서 랜덤하게 하나의 Action을 선택한다. 물론 이 방법도 나쁘지 않다.
하지만 조금 더 영리하고 효과적인 방법이 없을까?
Upper-Confidence-Bound (UCB)
예를들어, Exploration을 수행할 때 랜덤하게 하나의 Action을 정하는 것이 아니라, Action value의 불확실성과 최적 Action의 될 잠재력에 따라서 Exploration을 수행하는 것이 더 효과적으로 보일 수 있다.
그렇다면 Action-value의 잠재력은 어떻게 계산할 것인가? 불확실성은 어떻게 계산할 것인가? UCB의 식은 아래와 같다.
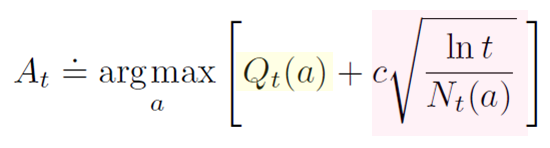
위 식의 첫번째 항이 잠재력을 나타내고, 두번째 항이 불확실성을 나타낸다.
Exloration을 할 때 단순히 랜덤하게 Action을 설정하는 것이 아니라, \(Q_t(a)\)로 Action value 추정값을 이용하여 각 Action의 Optimal Action이 될 잠재력을 감안한다.
불확실성은 위 식의 제곱근 항이 나타낸다. 불확실성은 다르게 표현하면 신뢰수준으로 이야기할 수 있다. 10000번의 Test를 한 결과와 10번의 Test를 한 결과는 신뢰성 부분에서 큰 차이를 보인다. 이와 마찬가지로 UCB는 \(N_t(a)\)을 통해서 t 시각 이전에 Action a가 몇번 선택되었는지를 나타내며 \(ln(t)\)를 통해서 전체 Sampling 횟수를 나타낸다. \(c\)는 c>0의 값으로 Exploration의 정도를 조정한다. 불확실성의 반영도라 생각할 수 있다.
Action a가 시간 t 동안 굉장히 많은 선택을 받았다면 그 신뢰수준을 높아질 것이다.
반면에 Action a가 b/c/d와 같이 다른 Action이 선택될 대마다 분자의 시간 t는 증가하지만 Action a가 선택된 횟수는 동일하므로 그 신뢰수준은 낮아질 것이다.
결국 모든 행동이 선택되지만 Action value의 추정값이 작거나 이미 많이 선택된 Action은 선택되는 빈도가 작아지게된다.
UCB vs ε-greedy
10-armed test에서 UCB와 ε-greedy를 사용한 결과가 아래의 그림이다.
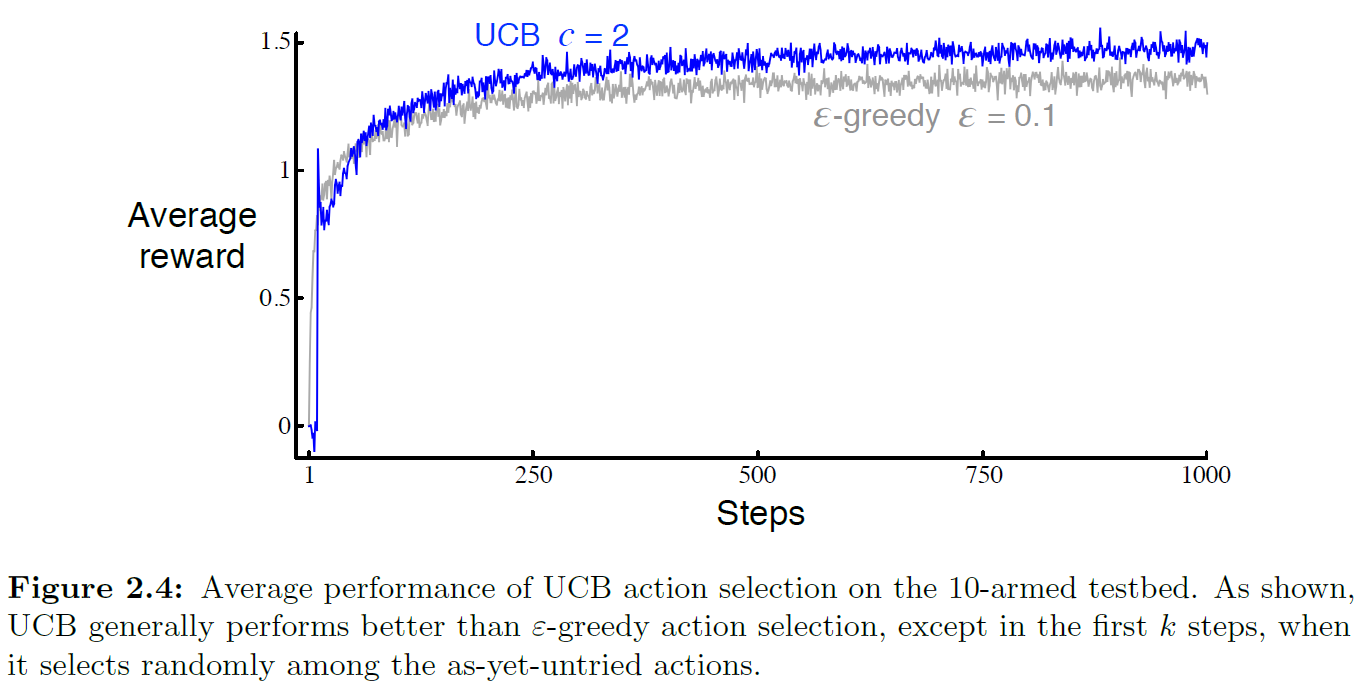
UCB의 성능이 ε-greedy의 성능보다 더 좋은 결과를 보인다.
그렇다면, 항상 UCB가 ε-greedy보다 더 좋은 방법일까? 그건 아니다. 대부분의 강화학습의 문제는 예제로 다루는 문제들과는 달리 매우 큰 State-space를 가지고 있다. 이럴 경우 불확실성을 표현하는것이 매우 어렵다. 따라서 일반적인 강화학습의 문제에서는 ε-greedy 방법을 더 많이 채택한다.
하지만, UCB에서 배울 수 있는 것은 '어떻게하면 더 효과적인 Exploration을 할 수 있을까?'에 대한 고민을 할 수 있게 해준다.